

JuniorG
Membro
-
Registro em
-
Última visita
-
Olá pessoal, Estamos abrindo um beta fechado e gratuito do nosso novo módulo Nota Fiscal SP (NFS-e) para WHMCS, desenvolvido para automatizar a emissão de NFS-e em São Paulo capital, usando a Nota do Milhão / Nota Paulistana. A proposta é atender empresas que usam WHMCS e precisam emitir nota fiscal de serviço pela Prefeitura de São Paulo, com integração direta ao Web Service oficial, sem depender de plataforma intermediária de emissão fiscal. Principal diferencialO módulo não cobra por NFS-e emitida. Ou seja: Sem mensalidade de API de terceiros Sem pacote de notas Sem cobrança por NFS-e emitida Sem limite de emissão pelo módulo Sem taxa adicional por nota fiscalDurante o beta, a licença será gratuita. Quem participar, testar e enviar feedback receberá 1 ano de licença da versão final sem custo. ScreenshotsFatura no admin com botões da NFS-e Configurações do módulo Fatura do cliente com XML e PDF da NFS-e Notas emitidas / cancelamento / reenvio de e-mail Histórico imutável de RPS O que o módulo fazO módulo já conta com as principais funções para uso real em WHMCS: Emissão automática de NFS-e quando a fatura é paga; Emissão manual diretamente pela tela da fatura no admin; Emissão manual também para faturas ainda não pagas, caso o operador queira emitir antecipadamente; Fila/cron para processamento e retentativas; Integração direta com o Web Service da Prefeitura de São Paulo; Suporte a certificado digital A1 .pfx / .p12; Ambiente de homologação e produção; Assinatura digital do RPS e do XML conforme exigência da Prefeitura; Cancelamento de NFS-e pelo painel; Download do XML da NFS-e; Link para visualizar o PDF oficial da NFS-e no portal da Prefeitura; Histórico imutável de RPS e tentativas de emissão; Logs internos para auditoria e diagnóstico; Elegibilidade por grupo de cliente ou campo customizado; Configuração de código de serviço, alíquota, tributação, série e tipo de RPS; Envio de e-mail ao cliente com link da NFS-e e XML; Proteção contra reemissão duplicada da mesma fatura. Integração direta com a Prefeitura de São PauloO módulo foi desenvolvido especificamente para a NFS-e de São Paulo capital, usando o Web Service da Prefeitura. Ele não depende de APIs intermediárias como plataformas fiscais terceirizadas. Isso reduz custo recorrente para quem emite volume maior de notas, já que não existe cobrança por pacote de notas nem valor adicional por emissão. O foco é: São Paulo/SP Nota do Milhão / Nota Paulistana Prestadores de serviço que usam WHMCS Para quem é indicadoEste beta é indicado para empresas que: Usam WHMCS; Prestam serviço em São Paulo capital; Emitem NFS-e pela Nota do Milhão; Possuem certificado digital A1; Querem automatizar a emissão após pagamento da fatura; Querem emitir manualmente quando necessário; Querem evitar custo por volume de notas fiscais emitidas. Como será o betaA liberação será feita para poucos participantes inicialmente, para conseguirmos acompanhar cada instalação com segurança. Durante o beta: Licença gratuita Sem cobrança por nota Sem limite de NFS-e pelo módulo Arquivos de instalação fornecidos diretamente Licença beta emitida manualmente Feedback direto para ajustes e melhoriasQuem participar do beta, testar o módulo e enviar feedback receberá 1 ano de licença da versão final sem custo. Observação importanteO módulo automatiza o envio de RPS/NFS-e com base nas configurações feitas no WHMCS. A responsabilidade pela configuração fiscal, como código de serviço, alíquota, tributação, retenção de ISS, dados do tomador e validação contábil, continua sendo da empresa usuária. Recomendamos validar as configurações com a contabilidade antes de usar em produção. Como participarPara participar do beta, basta enviar uma PM aqui pelo Portal do Host com: URL da sua empresa/WHMCS: E-mail de contato:Após recebermos as informações, vamos gerar uma licença beta gratuita e enviar os arquivos de instalação do módulo junto com as instruções iniciais. A liberação será feita de forma gradual para acompanharmos cada instalação e corrigirmos eventuais ajustes antes da versão final.
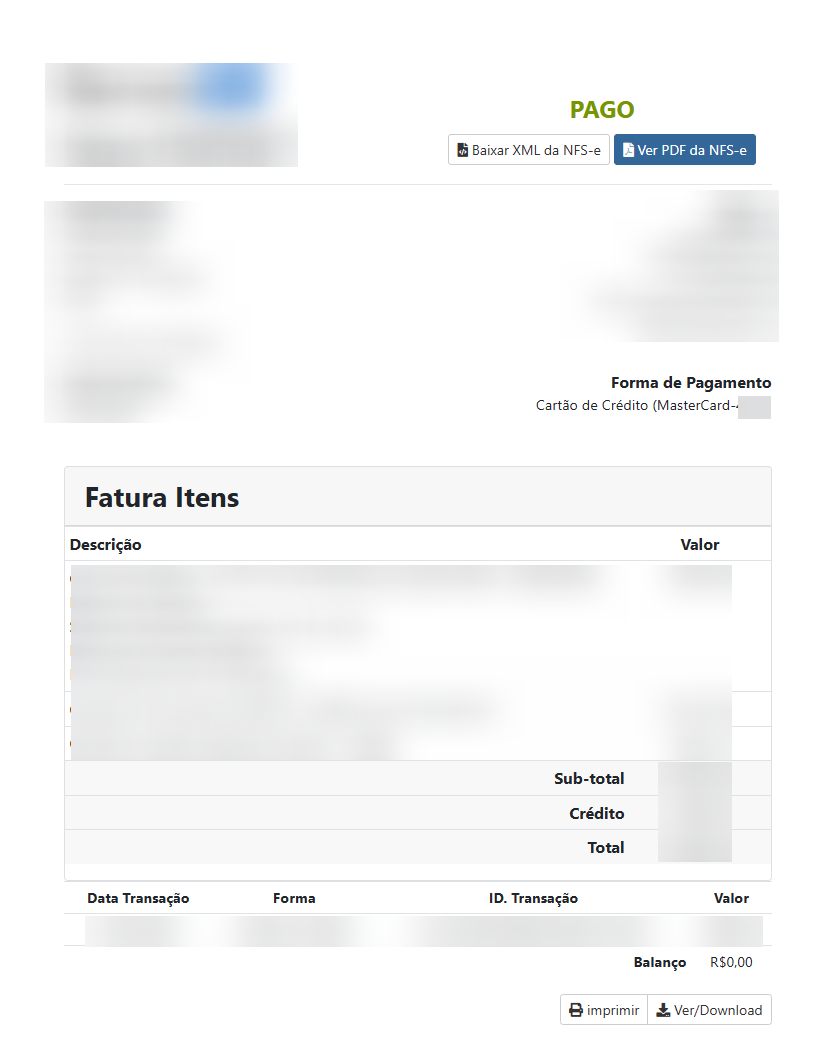
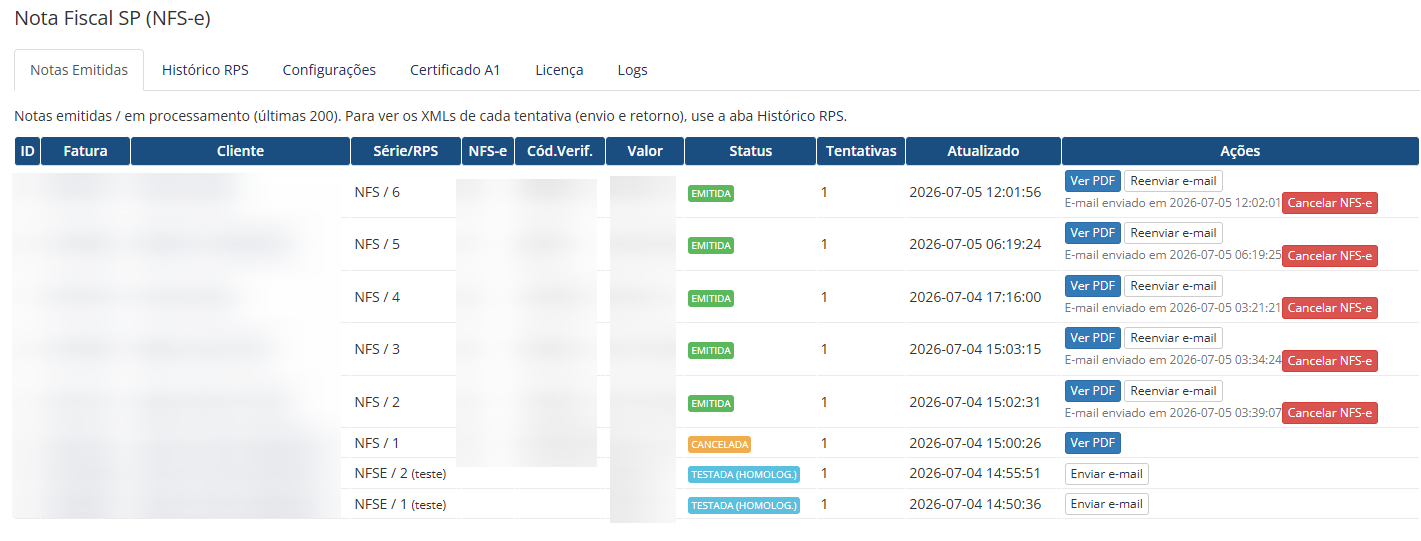
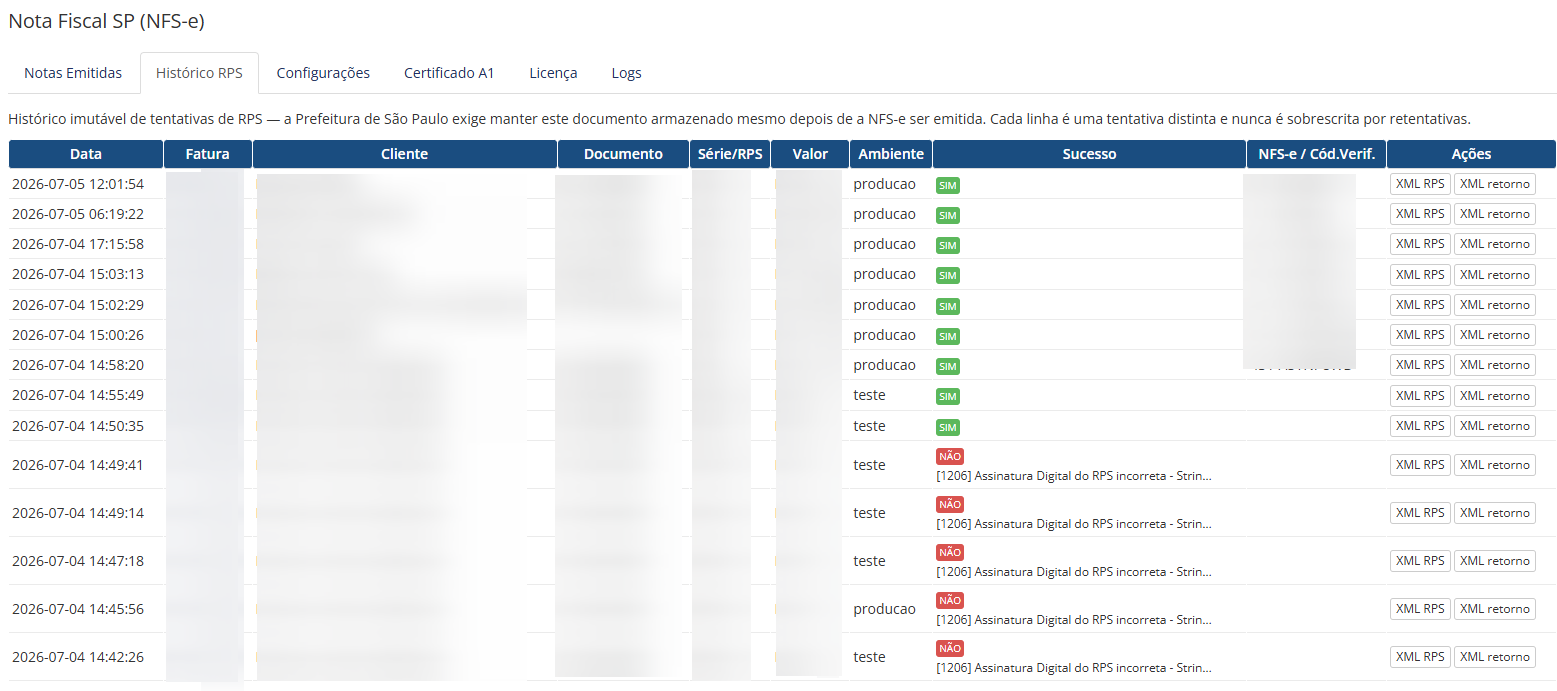

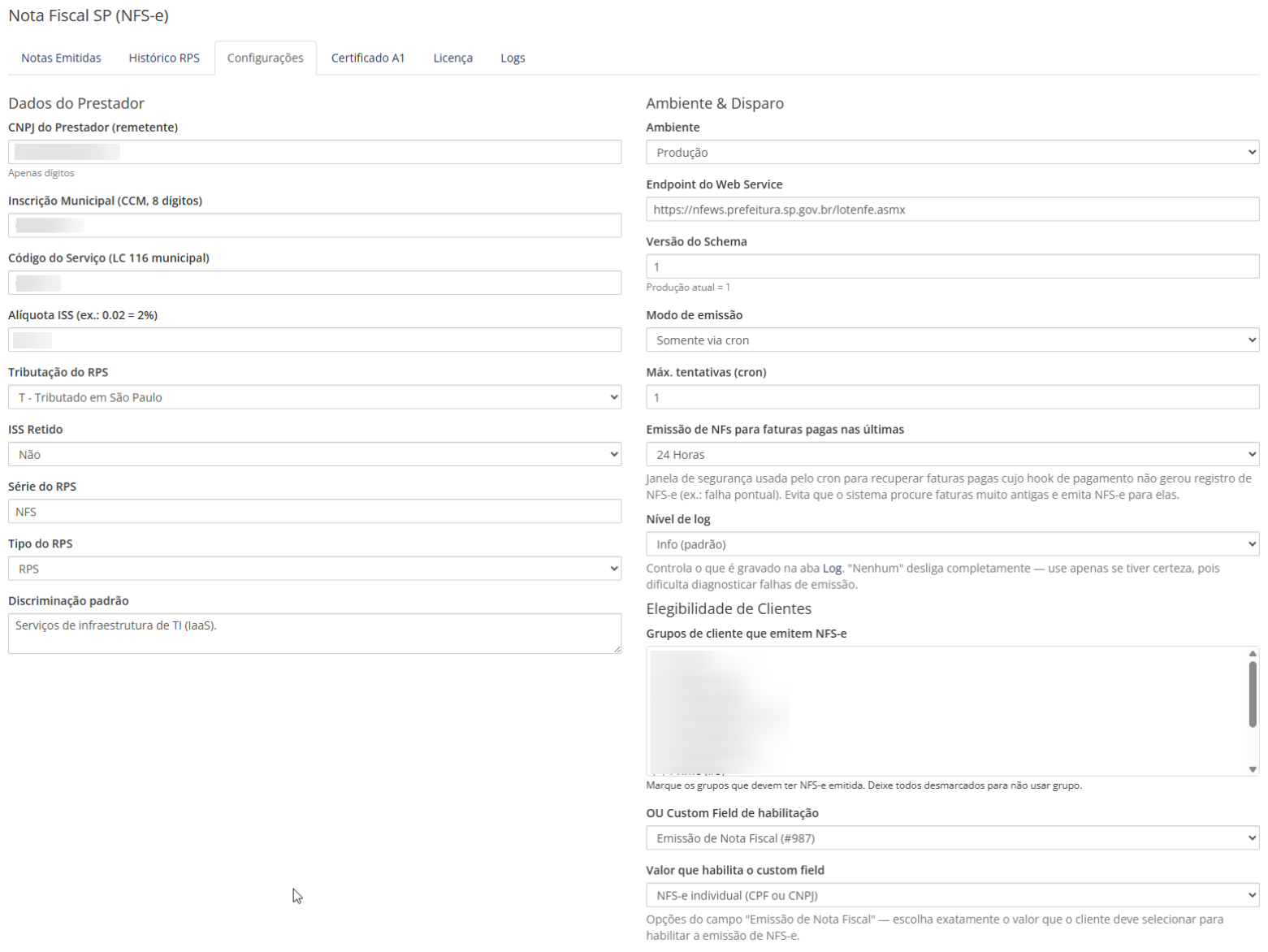
-
Te mandei MP, temos licença por R$99/m para até 250 clientes.
-
Notei que a Telefónica Celular da Bolívia foi a única operadora do grupo Telefónica na América do Sul que não apresentou perdas durante o incidente. Ao analisar a rota, percebi que o tempo de resposta está cerca de duas vezes maior que o normal, normalmente em torno de 90 ms, mas agora chegando a 180 ms. Executei um traceroute para confirmar o caminho e encontrei a seguinte rota: Miami-FL (Cogent) → Telefónica/Telxius Dallas-TX → Havana (Cuba) → Osasco (SP) → Paraguai → Telefónica Celular de Bolivia S.A. Ou seja, apesar da latência elevada, não há perda de pacotes, a rota está funcional, apenas mais longa que o habitual. Com certeza eles já estão trabalhando para resolver isso. Esse POP atende vários países da América do Sul, então qualquer falha ali acaba afetando múltiplas operadoras ao mesmo tempo.

-
Não estamos na OVH, mas temos um Smokeping para monitorar nossa infra em Miami e, por curiosidade fui analisar a conectividade com a América do Sul. Notei que todas as operadoras que dependem da Telefónica estão apresentando problemas. Durante o período entre 18:20 e 18:40 (UTC), foi possível observar instabilidade generalizada nas rotas que passam pela Telefónica International Wholesale Services (TIWS – AS12956), que é o backbone internacional do grupo Telefónica/Vivo. Essa rede é responsável por transportar o tráfego internacional da Vivo (Brasil), Movistar (América Latina) e outras operadoras do grupo até os pontos de interconexão com grandes provedores, como OVH, Cogent, Lumen, entre outros. Praticamente todos os ASNs ligados à Telefónica (Brasil, Argentina, Chile, Peru, Uruguai, entre outros) apresentaram aumento de latência e perda de pacotes no mesmo intervalo. Já os demais provedores (GlobeNet, Claro, CABO, Amazon, etc.) permaneceram estáveis, o que elimina qualquer problema no data center em Miami e aponta o gargalo diretamente para a TIWS.

-
No seu primeiro MTR mostra a rota saindo da Rede Local / VivoZap → Telefónica (TIWS) → 🇺🇸 OVH New Jersey (nyc-ny1) → 🇨🇦 OVH Beauharnois (BHS), então o ponto de falha está no handoff TIWS→OVH em NY/NJ ou já dentro do POP da OVH (nyc-ny1), e a perda segue até o Canadá (BHS). No segundo teste, usando AS263009 (Fortetelecom), a conexão sai do datacenter e entra diretamente na rede da OVH, com a rota: Fortetelecom (Brasil) → OVH (Denver → Virginia → Canadá). Consultei o AS263009 e eles têm peering direto com a OVH (AS16276) em algum IX, o que explica a rota diferente passando por Denver e evitando o caminho problemático por Miami. Tanto a OVH quanto a Vivo podem manipular as rotas para evitar o caminho congestionado, mas isso depende de uma ação manual de um dos lados.
-
Estava com um problema parecido há alguns meses. Era um congestionamento em uma parte da infraestrutura nos EUA, principalmente em Nova York, no link da HE. Como a OVH CA fica em Montreal, NY faz parte da rota, então acredito que o problema possa ter relação com isso. Quando o tráfego passava por um roteador da HE em NY, havia perda de até 80% dos pacotes. Entrei em contato com a HE e recebi a seguinte resposta: ==================== Hello, There is some congestion in the area during peak hours. We are adding additional capacity to alleviate this issue. ==================== No nosso caso, os servidores estão em Miami, então o problema ocorria na rota Miami ⇄ Canadá, enquanto a Miami ⇄ Brasil não apresentava perdas justamente por não depender de Nova York. Obs: A solução foi manipular a rota para preferir outro link de trânsito (Cogent), mantendo a HE apenas como backup. Seria interessante quem está enfrentando o problema fazer um MTR e postar o resultado, assim podemos analisar o caminho e identificar onde está o gargalo, para cobrar o responsável, seja o DC ou o próprio ISP.
-
Já tentou fazer um MTR pra confirmar onde é o problema?
-
Olá, Paghiper, suporta PIX e Boleto, no boleto tem a opção de PIX tbm, o módulo pra WHMCS é grátis!
-
Tem custo a API do C6?
-
Eu recebi o mesmo e-mail, no lowendtalk tem um pessoal conversando sobre isso.
-
Na prática, não possível anunciar blocos menores que /24. E para isso você precisaria ter um ASN e contratar trânsito IP, o que não é possível em conexões residenciais comuns como banda larga. Ou seja, se a ideia é montar algo barato, está bem longe do objetivo. Como já foi mencionado por outros, usar colocation em um DC acaba sendo mais viável. Agora, se o objetivo for apenas estudar, testar ou montar algo do tipo “sim, funciona e fui eu que fiz”, aí vale sim a pena. Nesse caso, você pode alugar um bloco pequeno (/29, /28 etc.) de qualquer provedor e fazer o roteamento até sua casa via túnel (como GRE ou WireGuard). Isso permitiria alocar IPs públicos às suas VPSs locais, é uma ótima maneira de aprender mais sobre redes, roteamento e infraestrutura.
-
Pelo que entendi, você utiliza um servidor dedicado para virtualização, e um dos seus clientes, que possui uma VPS, está enviando SPAM, o que está afetando a reputação dos seus IPs. Caso essas VPSs não sejam gerenciadas por você, uma forma simples e eficaz de mitigar o problema é bloquear a saída na porta 25 (SMTP) por padrão. Você pode então liberar essa porta manualmente apenas para clientes confiáveis, que não apresentem esse tipo de comportamento.
-
Realmente, por curiosidade, fui verificar onde está anunciado o IP 140.233.176.81 e notei que vários IPs do mesmo bloco possuem rDNS configurado com domínios listados pelo @chuvadenovembro Ao consultar o bloco completo 140.233.176.0/24, é possível ver que praticamente todos os IPs possuem PTR apontando para domínios .com.br. https://i.imgur.com/ZfJxS0p.png https://ipinfo.io/AS215026/140.233.176.0/24 Um detalhe interessante é que o bloco está com mnt-by: IPXO-MNT, indicando que provavelmente foi alugado via IPXO. A IPXO costuma ser bastante rígida quanto ao uso dos IPs para envio de spam, geralmente encerram o contrato após poucas denúncias. Sobre a empresa atualmente responsável (AS215026) por anunciar o bloco 140.233.176.0/24, se não estiver diretamente envolvida no abuso, no mínimo está sendo omissa. Se alguém tiver evidências de spam relacionado, vale a pena enviar uma denúncia: abuse@ walehost.com <= Empresa que está anunciando os blocos IPXO Abuse Report: https://www.ipxo.com/report-abuse/ <= Se a acima não resolver.
-
Fiz um projeto nesse estilo e vou compartilhar com você. Na parte física: No roteador da operadora (banda larga), coloquei em modo bridge para usar um Mikrotik RB5009 como roteador de borda. Uso um Juniper EX3300 para dividir as VLANs entre alguns servidores. Tenho um Dell T330 rodando Proxmox com algumas VMs, um Dell R630 que uso para testes, e mais um servidor Xeon "xing-ling". Na parte lógica: Como não posso usar a internet banda larga para anunciar IPs, configurei um túnel entre o Mikrotik de casa e o roteador de borda no datacenter. Esse roteador no DC tem BGP com as operadoras de trânsito e é quem anuncia os IPs. Através desse túnel, estou transportando um bloco /27 até minha casa para usar nos servidores. Além disso, os servidores estão conectados ao Juniper, que faz a separação por VLANs. Também passo várias VLANs para o T330, pois estou dedicando uma VLAN para algumas VMs (apenas para testes). Dentro do Proxmox, ainda tenho uma VM rodando CHR, que funciona como um segundo roteador interno. Resumo: Mesmo usando uma banda larga residencial, consigo atribuir IPs públicos diretamente às VMs e servidores internos. Ainda tenho vVLAN separada exclusiva para o gerenciamento do IDRAC separando da VLAN publica, Uso esse ambiente como um laboratório real para testar qualquer mudança antes de aplicar no DC em produção. Conselho: Use nobreak em tudo! No ano passado, perdi uma placa-mãe de um Dell R630 por estar ligado direto na energia. Equipamentos: o que comentei, um roteador Mikrotik (barato e fácil de usar) e um switch gerenciável.
-
Mesmo sendo uma mudança de data center físico, hoje em dia é totalmente possível montar uma estrutura que permita migração de VPS online, sem gerar downtime. Por exemplo, dá pra configurar um túnel entre os dois data centers e criar um ambiente temporário onde as redes dos dois lados se comuniquem. Com isso, o provedor pode mover as VMs uma a uma, mantendo IP, MAC e conectividade durante a migração. Isso é algo comum quando se quer evitar indisponibilidade para o cliente final.